
로딩 중이에요... 🐣
01 데이터 병합 조인 | ✅ 저자: 이유정(박사)
데이터 병합(조인)의 중요성
-
분석에 필요한 정보 통합
여러 테이블(또는 파일)에 흩어져 있는 데이터를 한 번에 다뤄야, 종합적인 인사이트를 얻을 수 있습니다. -
다양한 데이터 소스 결합
고객정보(프로필) + 거래정보(주문내역) + 클릭로그(웹사이트 행태) 등을 결합하면, 고객 행동과 매출 간의 연관성을 탐구할 수 있습니다. -
비즈니스 인사이트 강화
예를 들어 고객 데이터와 거래 데이터를 결합하면 “어떤 연령대, 어떤 지역의 고객이 어떤 상품을 선호하는가?” 같은 소비 패턴을 더 깊이 이해할 수 있습니다.
Pandas에서 제공하는 데이터 병합/조인 방법
-
merge
SQL의 JOIN과 유사하게, 열(column) 을 기준으로 다양한 종류의 조인을 지원 (inner,left,right,outer). -
join
기본적으로 인덱스(index)를 기준으로 왼쪽 조인(left)을 수행합니다 인덱스가 이미 조인 키로 최적화돼 있을 때 빠르게 작업 가능합니다 -
concat
단순히 데이터프레임을 위/옆으로 이어붙이는 기능. (행 행렬 단위로 붙이거나, 컬럼 단위로 합침)
join vs merge 와 속도 차이
-
join은 인덱스 기준 결합- 두 데이터프레임이 같은 인덱스를 갖고 있을 때, 왼쪽(
left) 기준으로 오른쪽 데이터를 “붙여” 줍니다. - 인덱스가 미리 정렬·최적화돼 있으면 아주 빠르게 동작합니다.
- 두 데이터프레임이 같은 인덱스를 갖고 있을 때, 왼쪽(
-
merge는 열(column) 기준 결합- SQL의 JOIN과 똑같이, 어떤 열을 기준으로 결합할지(
on=) 지정할 수 있습니다. - 내부조인(
inner), 왼쪽조인(left), 오른쪽조인(right), 외부조인(outer) 등 다양한 방식을 지원해 유연합니다.
- SQL의 JOIN과 똑같이, 어떤 열을 기준으로 결합할지(
-
속도 차이 요인
-
인덱스 최적화 여부:
join은 인덱스를 바로 찾아오기 때문에, 인덱스가 잘 준비돼 있으면 빠릅니다.merge는 각 행의 열 값을 비교해야 해, 데이터가 커질수록 느려집니다.
-
데이터 크기와 구조:
- 행 수가 수십만 건 이상인 대용량 데이터프레임에서는 조인 자체가 메모리와 시간 부담이 커집니다.
- 특히
outer조인은 결과 행 수가 크게 늘어날 수 있어 더 느립니다.
-
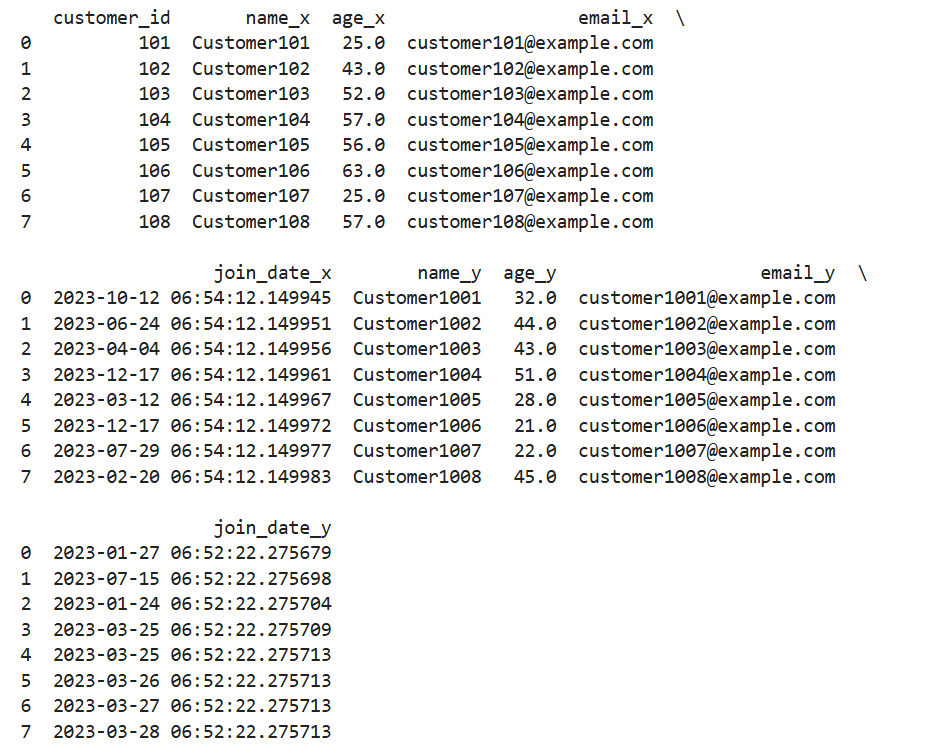
간단한 실습: merge는 옆으로(열 기준) 합치는 함수라서 두 테이블을 키(customer_id)에 따라 가로로 붙입니다.
import pandas as pd
df_1 = pd.read_csv("csv_files/combined_customers.csv")
df_2 = pd.read_csv("csv_files/combined_customers_added.csv")
merged_df = pd.merge(df_1, df_2, on='customer_id')
print(merged_df)
import pandas as pd
df_1 = pd.read_csv("csv_files/combined_customers.csv")
df_2 = pd.read_csv("csv_files/combined_customers_added.csv")
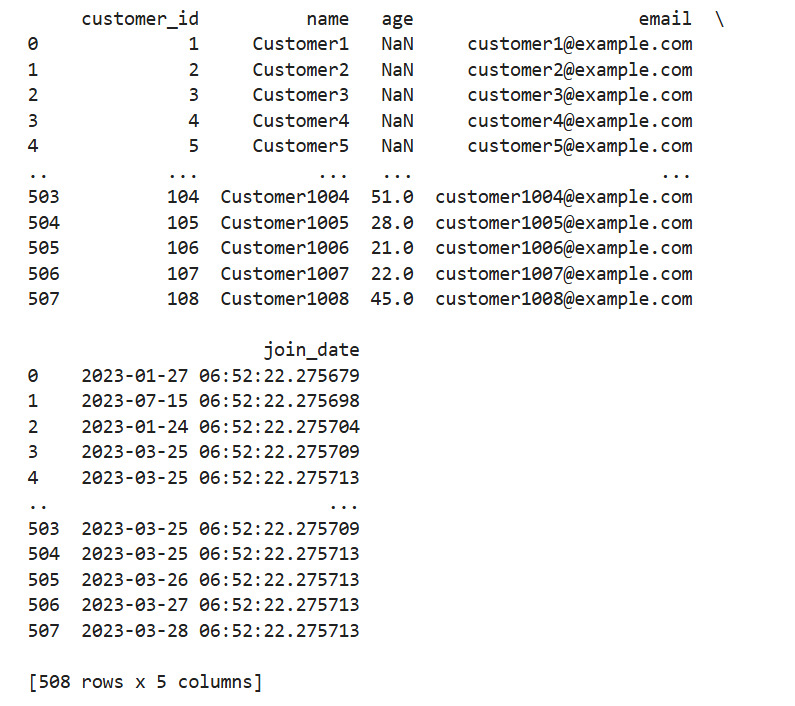
# 행 방향(axis=0)으로 아래로 이어붙이기
vertical_concat = pd.concat(
[df_1, df_2], # (1) 합치고 싶은 데이터프레임 리스트
axis=0, # (2) axis=0 → “행 방향”으로(concatenate rows) 이어붙임
ignore_index=True # (3) 새로운 인덱스를 0부터 순서대로 다시 매겨라
)
print(vertical_concat)
-
[df_1, df_2]pd.concat에는 합치고 싶은 데이터프레임을 리스트 형태로 넘깁니다.- 여기서는
combined_customers.csv에서 읽은df_1과, 추가 데이터를 읽은df_2를 한 번에 처리하겠다는 뜻입니다.
-
axis=0- 기본값이
axis=0이지만, 명시적으로 써 주면 “행을 따라” 합친다는 의미가 분명해집니다. - 즉,
df_2의 첫 행이df_1의 마지막 행 바로 아래에 붙게 됩니다.
- 기본값이
-
ignore_index=True- 원래
df_1과df_2는 각각 0,1,2… 로 시작하는 인덱스를 갖고 있었습니다. ignore_index=True를 쓰면 “이전 인덱스는 버리고, 결과 데이터프레임에는 0부터 연속된 인덱스를 새로 부여하라”는 옵션입니다.- 덕분에 중복되거나 건너뛰기 있는 기존 인덱스 대신 깔끔한 순번 인덱스(0,1,2,3…)를 얻게 됩니다.
- 원래
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df_1 = pd.read_csv("csv_files/combined_customers.csv")
df_2 = pd.read_csv("csv_files/combined_customers_added.csv")
merged_df = pd.merge(df_1, df_2, on='customer_id', how='outer')
plt.figure(figsize=(8, 4))
sns.heatmap(merged_df.isnull(), cbar=True, cmap='viridis')
plt.title('merged missing values')
plt.show()
how='outer' 조인을 썼기 때문에 양쪽(df_1과 df_2)에 존재하는 모든 customer_id를 합집합으로 가져오고,
각 DataFrame에 없는 정보는 NaN(결측치)로 채워집니다.
-
예를 들어 df_1에는 있지만 df_2에 없는 고객이 있으면,
그 고객의 df_2 쪽 컬럼(name_y,age_y등)에는 값이 없으니NaN이 됩니다. -
반대로 df_2에는 있지만 df_1에 없는 고객이 있으면,
df_1 쪽 컬럼(name_x,age_x등)에NaN이 생기구요.
결국 이 히트맵의 노란색(결측치)은
“이 customer_id는 한쪽 파일에만 있고, 다른 쪽에는 정보가 없어서 빈 칸으로 남았다” 는 패턴을 시각화한 것입니다.
-
만약
how='inner'로 하면 양쪽에 공통으로 있는 customer_id만 남기기 때문에, 결측치는 훨씬 줄어들거나 없어집니다. -
how='left'나right조인은 각각 왼쪽(df_1) 또는 오른쪽(df_2) 기준으로만 “모두 남기되” 반대쪽에 없으면 결측을 만들죠.
정리하자면, 외부 조인은 “없으면 빈칸(결측)” 을 일부러 만들면서까지 두 테이블을 합치는 방식이고, 이 때문에 isnull() 히트맵에 결측치가 보이는 겁니다.
outer 조인 vs inner 조인 차이
-
outer조인(전부 합치기)-
두 테이블의 모든
customer_id를 합집합(union) 으로 가져옵니다. -
즉,
df_1에만 있는 아이디 →df_2컬럼은NaN
df_2에만 있는 아이디 →df_1컬럼은NaN -
한쪽에만 존재하는 데이터에도 빈칸(결측치)을 허용하면서 모두 보여주기 때문에 결측치가 생깁니다.
-
-
inner조인(교집합)- 두 테이블에 공통으로 있는
customer_id만 결과에 포함시킵니다. - 따라서 양쪽 모두에 값이 있는 행만 남고,
“한쪽에만 있어서 결측이 발생할 행” 자체가 결과에 들어오지 않으므로 NaN이 전혀 생기지 않습니다.
- 두 테이블에 공통으로 있는
왜 inner 조인은 결측치가 사라졌을까?
how="inner"로 조인하면
“이 ID는
df_1에도 있고df_2에도 있는 ID만 모아라”
이기 때문에, 조인 과정에서 결측치를 만드는 대상인 ‘한쪽에만 있는 ID’ 자체가 걸러져 버립니다.
결국 남는 모든 행은 “양쪽에 다 있는” 완전한 데이터이므로isnull()결과가 전부False가 되는 거죠.
전체코드:
import pandas as pd
# 1) 고객 데이터 로드
df_customers = pd.read_csv("csv_files/combined_customers.csv")
# 2) 주문 데이터 로드
df_orders = pd.read_csv("csv_files/combined_orders.csv")
# 3) merge: customer_id 열 기준으로 왼쪽조인
merged_left = pd.merge(
df_customers,
df_orders,
on="customer_id",
how="left" # 고객은 모두, 주문 없으면 NaN
)
print(">> merge(how='left') 결과 (첫 5행):")
print(merged_left.head(), "\n")
# 4) merge: 내부조인(inner) → 고객과 주문이 모두 있는 행만
merged_inner = pd.merge(
df_customers,
df_orders,
on="customer_id",
how="inner"
)
print(">> merge(how='inner') 결과 (첫 5행):")
print(merged_inner.head(), "\n")
# 5) join: 인덱스 기준 왼쪽조인
dc = df_customers.set_index("customer_id")
do = df_orders.set_index("customer_id")
joined = dc.join(do, how="left")
print(">> join (인덱스 기준 left join) 결과 (첫 5행):")
print(joined.head(), "\n")
# 6) concat: 데이터프레임을 위/옆으로 이어붙이기
# (a) 행 방향(axis=0): 고객 데이터를 앞·뒤로 잘라 붙이기
concat_rows = pd.concat([df_customers.head(3), df_customers.tail(3)], axis=0)
print(">> concat 행(axis=0) 결과:")
print(concat_rows, "\n")
# (b) 열 방향(axis=1): 이메일과 가입일 컬럼만 뽑아 옆으로 붙이기
emails = df_customers[["customer_id", "email"]].set_index("customer_id")
join_dates = df_customers[["customer_id", "join_date"]].set_index("customer_id")
concat_cols = pd.concat([emails, join_dates], axis=1)
print(">> concat 열(axis=1) 결과 (첫 5행):")
print(concat_cols.head())
코드해석:
merged_left:
왼쪽 조인(Left Join) – 모든 고객은 유지하고, 주문 정보가 없으면 NaN으로 표시
# 3) merge: customer_id 열 기준으로 왼쪽조인
merged_left = pd.merge(
df_customers,
orders,
on="customer_id",
how="left" # 고객은 모두, 주문 없으면 NaN
)
print(">> merge(how='left') 결과 (첫 5행):")
print(merged_left.head(), "\n")
-
pd.merge(…)- Pandas의
merge함수는 SQL의 JOIN과 거의 동일하게 동작합니다. - 첫 번째 인자와 두 번째 인자에 합치고 싶은 두 데이터프레임을 순서대로 전달합니다.
- Pandas의
-
on="customer_id"- 두 데이터프레임 모두에 있는
customer_id열을 “키(key)”로 삼아 결합합니다. - 예를 들어
customer_id = 1인 고객 정보 행과customer_id = 1인 주문 내역 행이 만나서 하나의 행으로 합쳐집니다.
- 두 데이터프레임 모두에 있는
-
how="left"(왼쪽조인)- “왼쪽조인”이란, 첫 번째 데이터프레임(
df_customers)에 있는 모든 고객을 결과에 그대로 남기되, 두 번째 데이터프레임(orders)에 주문 기록이 있으면 그 값을 붙이고, 없으면order_amount,order_date열에NaN(빈 값)이 들어가도록 하는 방식입니다. - 즉 “고객은 모두 표시하되, 주문 내역이 있으면 보여주고, 없으면 빈칸으로 남긴다”는 의미입니다.
- “왼쪽조인”이란, 첫 번째 데이터프레임(
출력결과 예시: merged_left.head()는 합쳐진 데이터프레임의 첫 5행만 보여줌
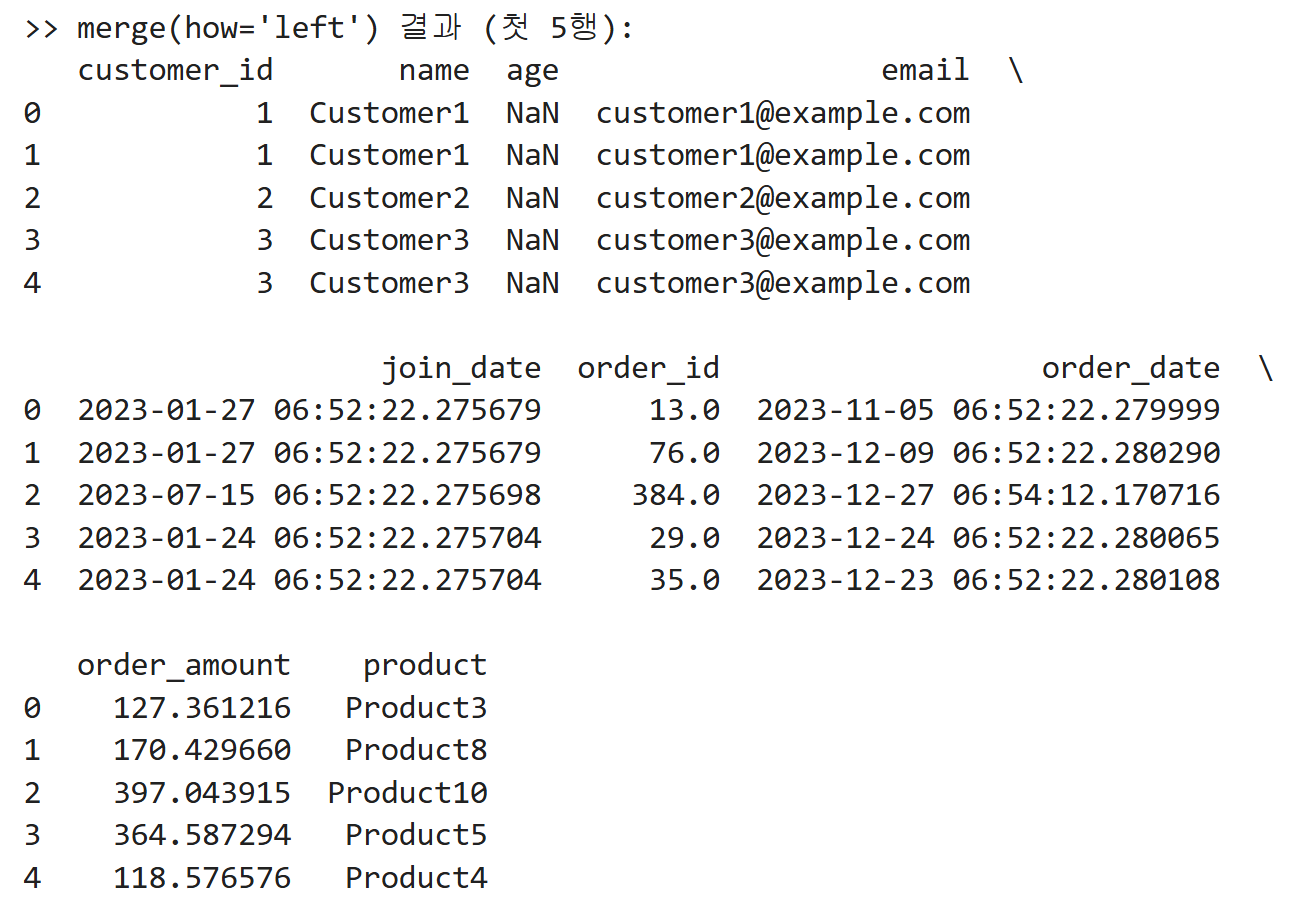
df_customers의 모든 고객 행을 결과에 포함하고orders에 해당customer_id가 있으면 주문 정보를 붙여 넣으며, 없으면NaN으로 채웁니다.- 한 고객이 주문을 여러 건 하면 그 수만큼 고객 정보가 반복되어 나타납니다.
merged_inner: 내부 조인(Inner Join) – 고객과 주문이 모두 있는 데이터만 포함
# 4) merge: 내부조인(inner) → 고객과 주문이 모두 있는 행만
merged_inner = pd.merge(
df_customers, # ① 고객 정보 데이터프레임
orders, # ② 주문 내역 데이터프레임
on="customer_id", # ③ customer_id 열을 기준으로 결합
how="inner" # ④ 내부조인: 두 데이터프레임에 모두 존재하는 키 값만
)
print(">> merge(how='inner') 결과 (첫 5행):")
print(merged_inner.head(), "\n")
-
pd.merge(...)merge함수는 SQL의 JOIN과 같으며, 두 데이터프레임을 지정한 키 열(on="customer_id")로 합칩니다.
-
how="inner"- 내부조인은 “양쪽에 모두 존재하는 키만 남긴다”는 의미입니다.
- 즉,
df_customers에도orders에도customer_id가 같은 행이 있을 때만 그 행을 결과에 포함시킵니다. - 고객 정보는 있지만 주문이 없는 고객, 또는 주문은 있지만 고객 정보가 없는 주문 기록 모두 결과에서 제외됩니다.
예시 출력 (첫 5행)
아래는 merged_inner.head() 를 실행했을 때 볼 수 있는 예시입니다.
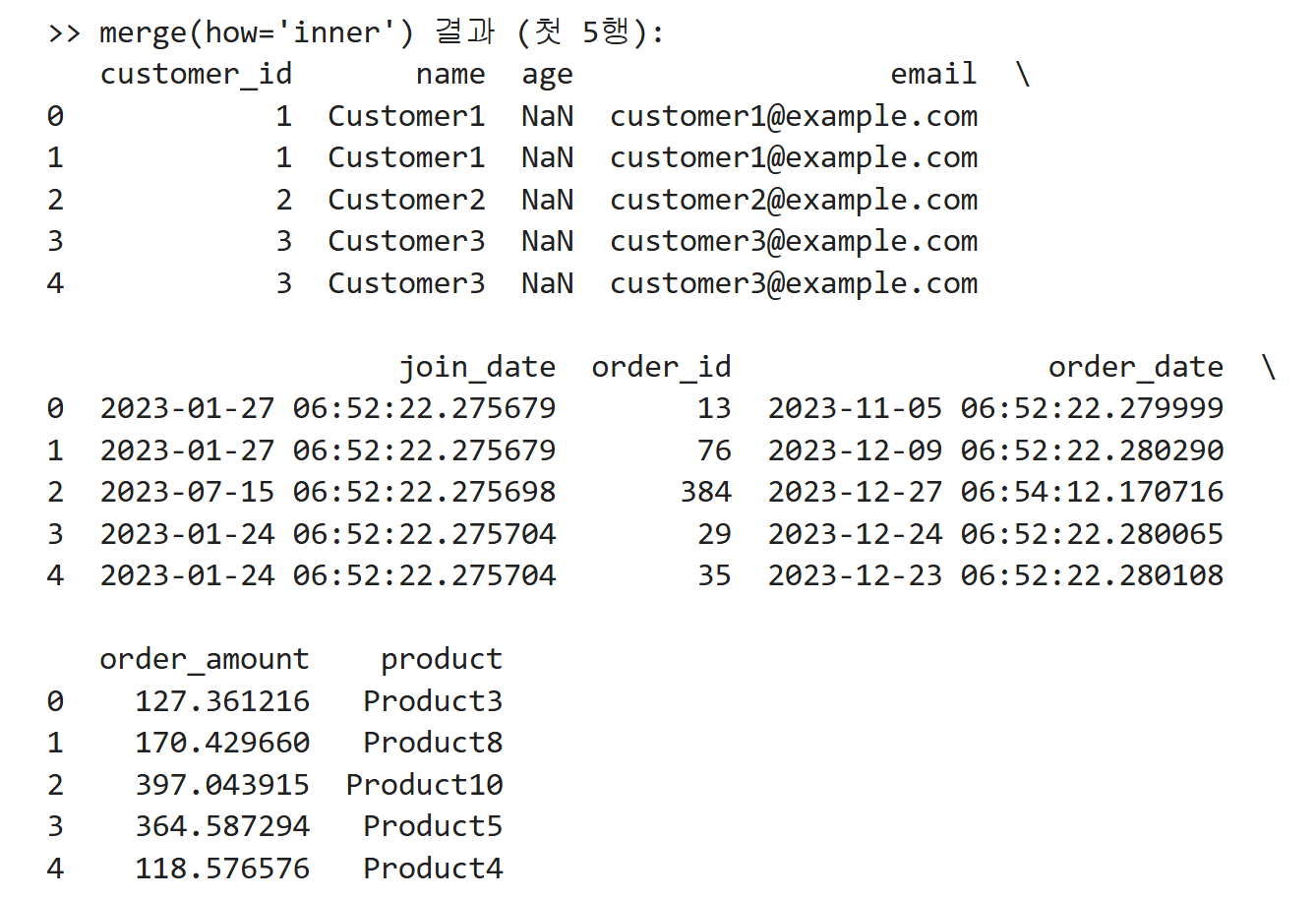
pd.merge(..., how="inner")는 양쪽 데이터프레임 모두에 존재하는customer_id값만 남기고- 고객 정보만 있거나 주문 정보만 있는 행은 결과에서 제외합니다.
- 복수 주문이 있는 고객은 주문 건수만큼 행이 반복 출력됩니다.
joined: 인덱스 기준 왼쪽 조인(Index‑based Left Join) 인덱스를 이용해 고객 정보 우선 결합
# 5) join: 인덱스 기준 왼쪽조인
# 인덱스로 사용하기 위해 reset_index → set_index 진행
# (1) df_customers에서 customer_id를 인덱스로 설정
dc = df_customers.set_index("customer_id")
# (2) orders에서 customer_id를 인덱스로 설정
do = orders.set_index("customer_id")
# (3) 인덱스 기준으로 왼쪽조인
joined = dc.join(do, how="left")
# (4) 결과 확인
print(">> join (인덱스 기준 left join) 결과 (첫 5행):")
print(joined.head(), "\n")
-
set_index("customer_id")- 원래
df_customers와orders는customer_id가 일반 컬럼(column)으로 들어 있습니다. set_index를 사용하면 그 컬럼을 행 인덱스로 바꿔 줍니다.- 이렇게 하면 Pandas가 행을 찾을 때 인덱스 값만 비교하면 돼서,
join이 더 빠르게 동작할 수 있습니다.
- 원래
-
dc.join(do, how="left")dc.join(do)는dc의 인덱스를 기준으로do를 왼쪽조인 합니다.how="left"옵션 덕분에dc(고객 정보)에 있는 모든 인덱스(고객)를 결과에 그대로 남기고,do(주문 내역)에 해당 인덱스가 있으면 값을 붙이고, 없으면NaN이 들어갑니다.
-
출력 결과
joined.head()는 합친 뒤 처음 다섯 행을 보여 줍니다.- 예를 들어
customer_id = 1이면 주문 정보가 같이 붙고, - 주문이 없는
customer_id = 3,4 ...는order_amount,order_date칸이NaN으로 표시되는 것을 확인할 수 있습니다.
언제 쓰나?
-
데이터프레임들이 이미 인덱스로 결합 키를 갖고 있을 때
join이 간편합니다. -
인덱스가 잘 정리되어 있으면
merge보다 약간 더 빠를 수 있습니다. -
코드도 짧아지고, “왼쪽 기준으로 붙인다”는 의도가 분명해 초보자도 이해하기 쉽습니다.
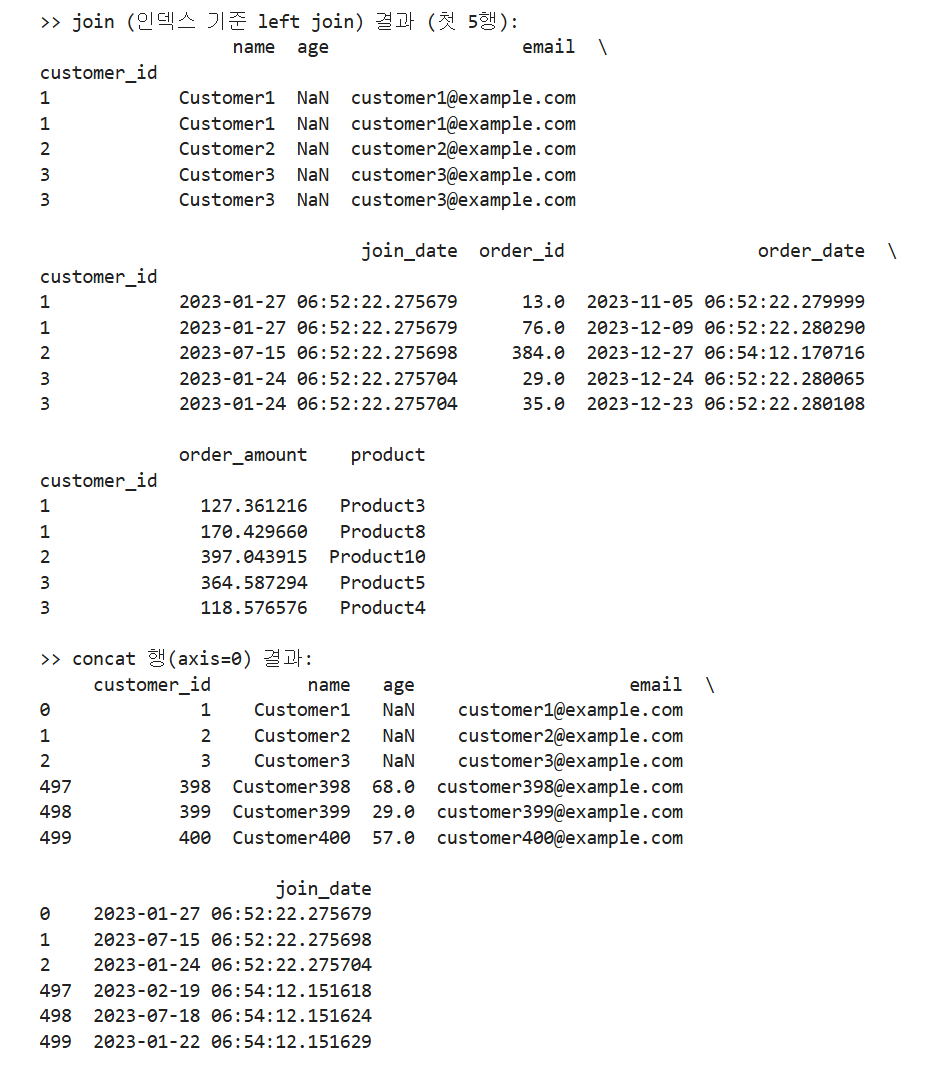
-
set_index("customer_id")로customer_id를 인덱스로 옮기면, 그 인덱스를 기준으로 빠르게 결합할 수 있습니다. -
dc.join(do, how="left")는 “왼쪽(고객) 인덱스를 모두 유지하면서, 오른쪽(주문)에 같은 인덱스가 있으면 붙이고 없으면 NaN”을 적용합니다. -
결과에서 주문이 여러 건 있는 고객은 고객 정보가 주문 건수만큼 반복되고, 주문 없는 고객은 주문 칸이 NaN으로 표시됩니다.
concat_rows: 행 연결(Row Concatenation) 데이터프레임을 위아래로 차례로 이어붙임
# 6) concat: 데이터프레임을 위/옆으로 이어붙이기
# (a) 행 방향(axis=0): 고객 데이터를 두 번 합쳐 보기
concat_rows = pd.concat(
[ df_customers.head(3), # (1) 고객 데이터의 첫 3행
df_customers.tail(3) ], # (2) 고객 데이터의 마지막 3행
axis=0 # (3) axis=0 → “행 방향”으로 이어붙임
)
# axis=0 행 방향, index 축
# axis=1 열 방향, column 축
print(">> concat 행(axis=0) 결과:")
print(concat_rows, "\n")
-
df_customers.head(3)- 원본 고객 데이터프레임에서 “첫 3행”만 잘라서 가져옵니다.
- 예를 들어, 고객 ID 1, 2, 3의 정보가 담겨 있겠죠.
-
df_customers.tail(3)- 반대로, “마지막 3행”만 잘라서 가져옵니다.
- 예를 들어, 데이터가 43행까지 있다면 고객 ID 41, 42, 43의 정보가 됩니다.
-
pd.concat([...], axis=0)pd.concat함수에 두 개의 작은 데이터프레임을 리스트로 넘깁니다.axis=0옵션은 “행 방향(row-wise)”을 의미해서,- 첫 번째 조각(첫 3행)을 맨 위에,
- 두 번째 조각(마지막 3행)을 그 아래에
차례로 붙여 줍니다.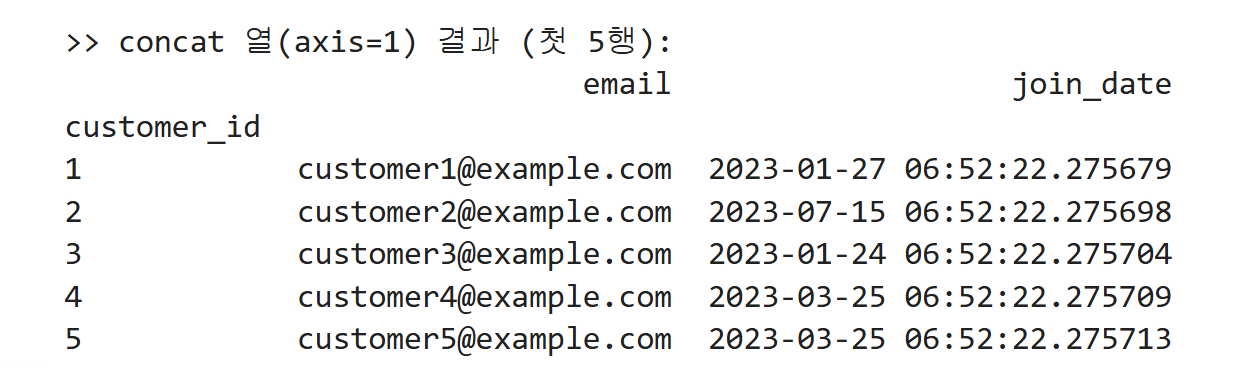
-
df_customers.head(3)로 처음 3행을,df_customers.tail(3)로 마지막 3행을 잘라오고 -
pd.concat([...], axis=0)는 이 두 조각을 위아래(행 방향)로 이어붙입니다. -
결과 데이터프레임에는 첫 3행이 맨 위에, 마지막 3행이 그 아래에 차례대로 위치합니다.
concat_cols: 열 연결(Column Concatenation) – 특정 컬럼끼리 좌우로 병렬 결합
# (b) 열 방향(axis=1): 이메일과 가입일 열을 병렬로 합쳐 보기
# (1) 이메일 정보만 뽑아서 인덱스를 customer_id로 설정
emails = df_customers[["customer_id", "email"]].set_index("customer_id")
# (2) 가입일(join_date) 정보만 뽑아서 인덱스를 customer_id로 설정
joins = df_customers[["customer_id", "join_date"]].set_index("customer_id")
# (3) 두 데이터프레임을 axis=1 (열 방향)으로 합치기
concat_cols = pd.concat([emails, joins], axis=1)
# (4) 결과 확인
print(">> concat 열(axis=1) 결과 (첫 5행):")
print(concat_cols.head())
-
df_customers[["customer_id", "email"]]- 고객 데이터에서
customer_id와email컬럼만 선택합니다.
- 고객 데이터에서
-
.set_index("customer_id")- 선택한 데이터프레임의
customer_id컬럼을 행 인덱스로 바꿔 줍니다. - 인덱스를 기준으로 결합하려는 두 테이블이 같은 인덱스를 가지면,
concat시 값이 정확히 매핑됩니다.
- 선택한 데이터프레임의
-
pd.concat([emails, joins], axis=1)axis=1옵션은 “열 방향(column-wise)” 이어붙임을 의미합니다.- 즉,
emails의 오른쪽에joins를 붙여서 한 데이터프레임으로 만듭니다. - 인덱스(고객 ID)가 같은 행끼리 나란히 결합됩니다. 결과물
-
최종
concat_cols는 고객 ID를 인덱스로 하여, 왼쪽 열은email, 오른쪽 열은join_date가 됩니다. -
print(concat_cols.head())로 보면 대략 다음과 같습니다: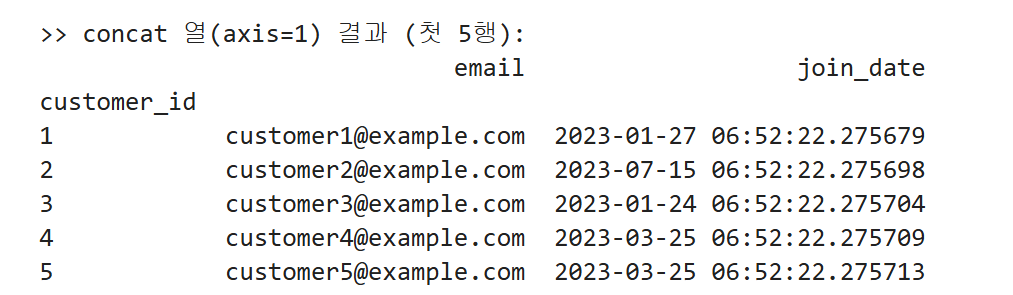 언제 사용하나요?
언제 사용하나요? -
동일 인덱스를 공유하는 서로 다른 속성(컬럼)들을 하나로 묶고 싶을 때 유용함
-
예를 들어, 고객 프로필에서 “이메일” 정보만 모은 테이블과 “가입일”만 모은 테이블이 있을 때, 이 둘을 합쳐서 한눈에 보고 싶을 때 씁니다.
-
axis=1방향은 기존 행(고객)을 그대로 유지하면서, 컬럼을 확장하는 방식입니다. -
df_customers[["customer_id", "email"]]와df_customers[["customer_id", "join_date"]]로 필요한 열만 떼어내고 -
각각
customer_id를 인덱스로 설정한 뒤 -
pd.concat([...], axis=1)으로 같은 인덱스끼리 나란히 붙이면 -
최종 결과는 인덱스(고객 ID)를 기준으로 왼쪽에
email, 오른쪽에join_date가 있는 데이터프레임이 됩니다.